
初识神经网络的分类问题
初识神经网络的分类问题
在接触分类问题之前,我们先学过了回归问题

- 回归问题是找一个神秘的函数关系,来匹配并预测每个数据点的位置
- 而分类问题是要寻找到一个方法,将数据集划分为若干类,每个类中都有神秘的共性,我们要找的模型就是区分他们的方法
以图片分类为例,我们给电脑投喂一组照片,里面有[猫,狗,树],但我们知道,机器学习的输出是数学形式,所以我们要使用One-hot独热编码来表示模型输出的结果

类似于计组中的指令编码方法,每一类表达不同的种类的概率,在上述例子中,每位分别表示图片为狗、猫、树的概率
简述训练流程的各种问题

输入一幅图片(图片天生就是矩阵),模型对矩阵进行预测,然后输出各个分类的概率,在对概率进行处理,最后得到分类的结果
如何理解图片作为输入源

所有颜色都可以通过RGB三维色彩坐标来表示,所以所有图片可以拆解为红绿蓝三层

对于不同中的像素点,对于该层的颜色来说,又有不同的灰度,这时的灰度值就作为这个该层中此像素点的值
但是在上次学的回归中,输入的都是一维张量,对于矩阵来说,我们同样可以将他们转换为一维的,只需要将每层的矩阵拉平,再将不同层拼接即可
训练模型的时候,常常将图片尺寸处理为224*224再喂给模型处理

一维?何不全连接?
都把图片降维成一维的了,为什么不直接用全连接找规律呢
哥们,想想模型的参数数量,224 224 3初始点位,就算是个层数不高的全连接,产生的参数数量也是非常惊人的,这代价未免也太大了

显然对于矩阵来说,全连接有点太过粗暴了
卷积神经网络
之前学图像处理的时候有接触过一些皮毛,不过当时在准备java的方向就也没认真听,只知道卷积核大概是怎么卷的

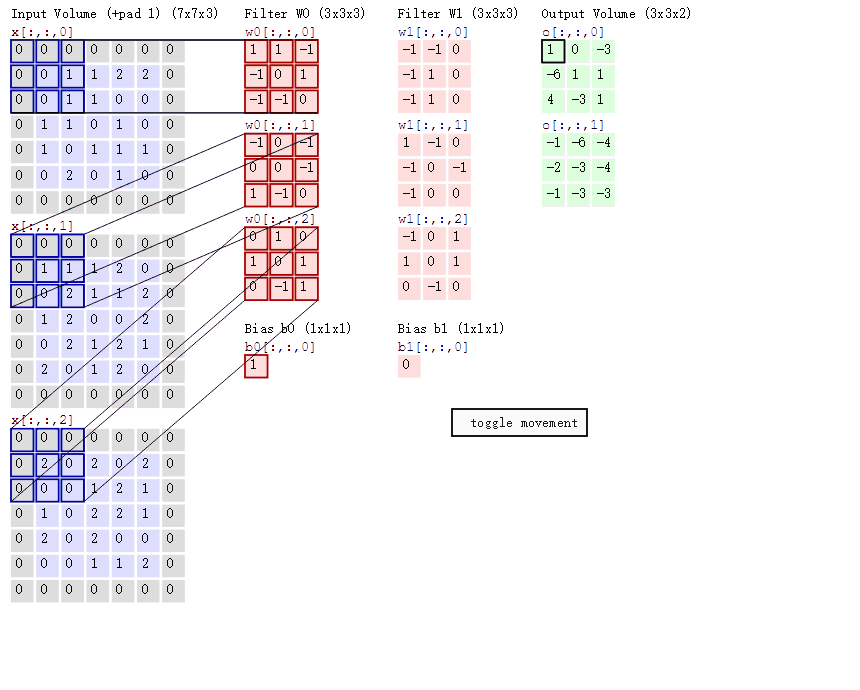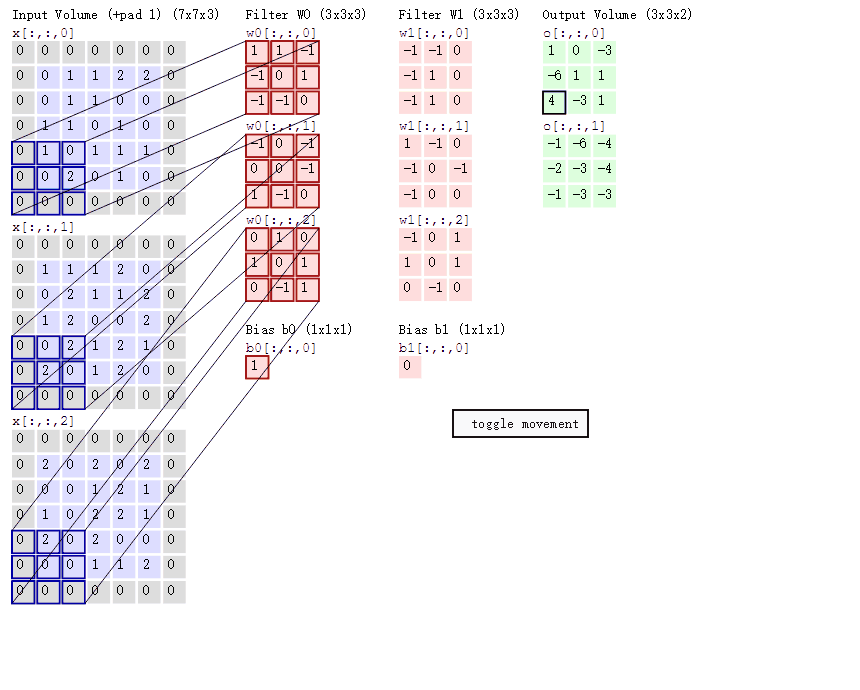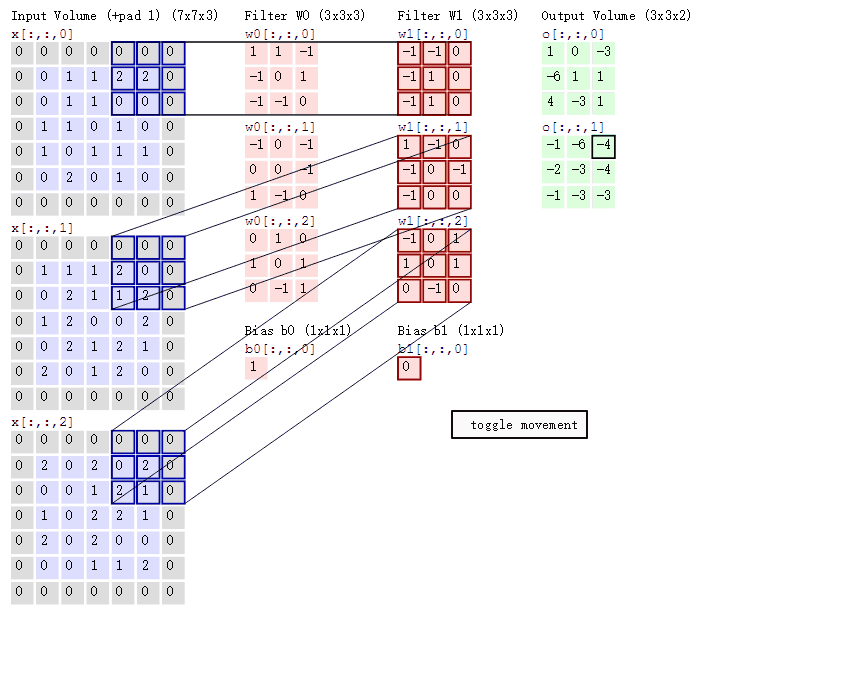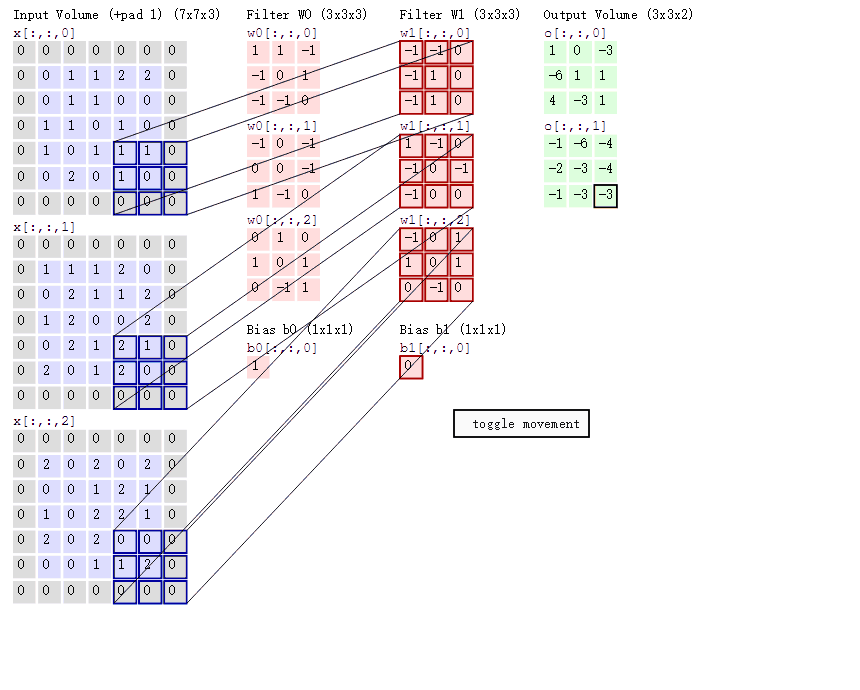
在上图中,我们将那个比较大的图作为特征图,下面那个小图作为卷积核,用红色表示1,黑色表示-1
这样就将抽象的图像用数字化的形式表述出来了,我们此时只需要将卷积核在合适的地方与特征图上的数对应相乘,最后将结果记录在新的特征图上即可
图片的所有组成部分都有意义吗
我们人脑辨认物体的时候,当然能窥见全貌是最好的,但如果只看见了物体的一部分,也能认出个大概,这部分内容,我们称之为特征


以这张鸟的图片为例,我们可以将鸟眼、鸟嘴、鸟胯子等等部位作为鸟的特征,并在神经网络的训练中给予这些特征不同的权重
毕竟单看这个鸟嘴的话,好像长在小鸡头上也不是不行

More About 卷积核
之前提到的卷积核,在上面的例子中,就相当于鸟胯子、鸟嘴、鸟眼
那么我们怎么选择合适的卷积核?
- 更大的卷积核可以拥有更大的感受野


我们将一张图片通过多个卷积核卷积过后,每个卷积核都各自生成了一张新的特征图,如果我们还想加深,接着卷,就把新生成的这些特征图叠加,继续循环往复,最后形成了下图右下角的克系特征图,已经超出人类能认识的维度了

如何缩小特征图?
方法1:扩大步长;相当与增加取样间隔,但是这样比较慢,而且没考虑到每步之间的数据

方法2:依靠Pooling池化

卷积后的尺寸计算
O = ( I - K + 2P ) / S + 1
O:卷积后新特征图边长
I:原特征图边长Input
K:卷积核边长
P:边距Padding
S:步长Stride
卷积如何计算出最后的类别?

先处理原图,然后输入到模型中进行学习,最后对对于每个类,输出一个数字
显然这里给出的结果不是对应的概率,这就需要对原始的Loss进行处理

在上面面的例子中,y的变换公式为yi^ = (e^yi)/(e^yi + e^yj + e^yk),显然这样就把原来数值之间的差距拉大了,得到了需要的输出结果
上面公式规范表述为
分类学习的过程中如何对模型进行优化?
使用交叉熵损失来计算LOSS

这里并不需要知道交叉熵到底是个啥玩意,直接看二分类的计算方法吧

显而易见的,Loss需要越小越好,而这里loss要取负号,所以对于大括号内的数,我们需要他越大越好
我们看训练集的结果
当y^=0,对应的y’ 表示预测错误,那么大括号里只剩下了

更具体地说,只剩下了log(1-y’ ),需要让他越大越好,所以y需要尽可能的小,换而言之,这与我们追求的缩小错误选项的概率不谋而合
同理,当y^=1,只剩下了-y^logy’,这里就需要y’越大越好~


